
Demanding Tech Factors in Formula 1: What Makes Motorsport's Data Game So Hard

Formula 1 does only race cars-it races data. Every grand prix weekend, teams ingest staggering volumes of telemetry, run simulations, and lean on models to shape strategy, reliability, and performance. The technical demands of this environment are extreme: real-time decisons, zero tolerance for failure, and relentless pressure to innovate within tight rules and budgets. Those same demands show up, in different form, in production machine learning.
Real-Time or Nothing: Latency as a Hard Constraint
In F1, strategy and pit-wall decisions happen in seconds. A safety car, a sudden rain shower, or a rival’s pit stop forces immediate recalculation of tire strategy, pit window, and race mode. There is no “We’ll run the model overnight.” The window for a pit stop call can be a handful laps; the window for updating a strategic recommendation is often sub-minute.
In reality, telemetry streams in at thousands of samples per second per car. Strategy tools must consume live data, run optimizations or predictions, and surface recommendations before the next lap is done. Late insights are therefore useless.
Production ML faces the same kind of latency budget. To win, you have to act faster than the competition. Batch-only pipelines are not enough when the business decision is “now.” You need:
Low latency inference, wherein the served model meets strict p95 targets.
Features that are computed and served in near real time, not just daily batch jobs.
Caching and pre-computation of multiple scenarios, to be prepared for when the event happens.

A single car can produce hundreds of channels of telemetry at high frequency. Multiply by two cars, multiple session, and 20+ races, and you get petabytes of structured time-series data. Add weather, timing, GPS< and historical archives, and the scale becomes overwhelming. The engineers must filter, aggregate, and store this data so it’s queryable for strategy, reliability, and driver analysis. Raw dumps are insufficient; the true value is in derived signals, lap-level features, and event-based indexes.
High-velocity, high-volume data is the norm in strong ML systems. The demanding factors are:
Feature stores - central, versioned feature definitions and backfills so training and serving use the same logic.
Incremental and streaming ETL - pipelines that can handle continuous ingestion without re-processing the entire history every time.
Data quality and schema evolution - new sensors (or new product events) must be integrated without breaking the existing models and dashboards.
F1’s “firehose” is a magnified version of what many MLOps teams face: if you can’t tame volume and velocity, you can’t build and reliable models or value adding real-time features.
The technical bar in F1 is high not because the sport is exotic, but because the constraints are universal: fast, reliable, auditable, and efficient. MLOps, when done well addresses the same set of demands-so the demanding tech factors in F1 are a useful lens for designing and running production ML systems that can perform when it matters.
Coding Exercise: Reliable Strategy Fallback (Circuit Breaker Pattern)
One of the most demanding factors in F1 is reliability under pressure: when the primary ML strategy service is slow or down, the pit wall still needs a recommendation. This exercise implements a simple circuit breaker with a fallback-a pattern that MLOps uses to keep systems reliable when dependencies fail.
Problem: Strategy Service with Fallback
Call a (simulated) strategy service that may be slow or fail.
If it fails or time out, fall back to a rule-based recommendation (e.g “Stay out” or “box next lap”).
Use a circuit breaker so we don’t hammer a failing service; after N failures, skip the call and go straight to fallback for a cooldown period.
Example:
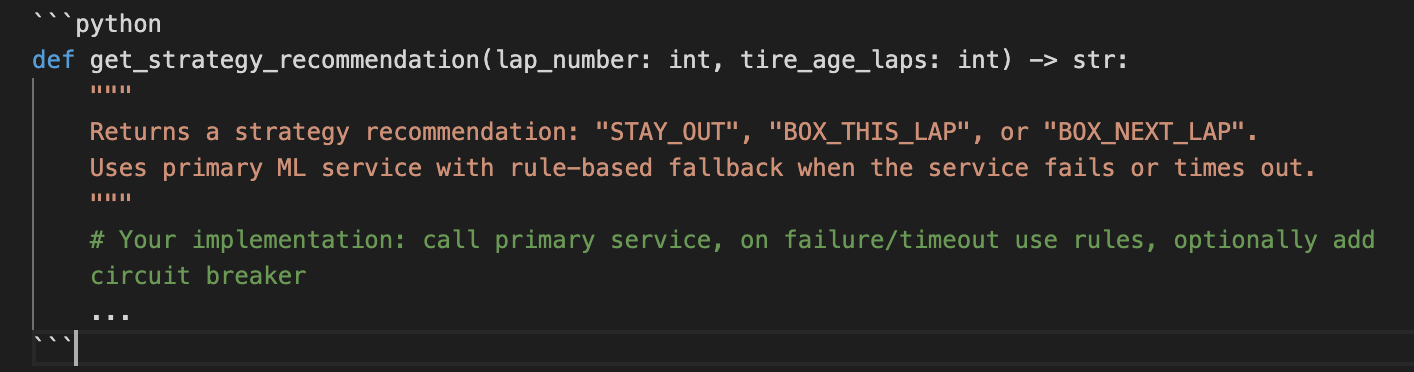
You can find a starting solution in the Github link here.
A fallback ensures a decision is always returned, even when the primary model or service fails. The circuit breaker avoids cascading failure and gives the failing service time to recover. In production, you would log when fallback is used and when the circuit opens/closes to help debug and improve the primary model.
The demanding factor here is the same as in F1: no redos on race day. MLOps must design for failure so that when the primary system does not deliver, the system still does.
The hardest part is not in building a model, but in making it work at the right time, with the right data, under real-world pressure.